Performance of Compound R/W RADOS Operations (Part 2)
TweetIn Part 1 of this series I looked at the cost of performing a guarded append operation on a single object with varying levels of concurrency. Without parallel journaling mode enabled, the performance of the guarded append doesn't scale with the number of clients writing because each operation dirties the object, forcing a flush to the data drive to satisfy the read necessary for guard. In contrast, an append-only workload scales well with the number of clients appending. With parallel journaling enabled the performance of the guarded appends levels off compared to the non-guarded append with four or more clients.
In order to scale a large number of guarded appends in the system one way is to stripe the appends over many objects, with the assumption being that less contention for a single object lets us scale the total number of guarded appends. Here is a comment from the ObjectStore.h interface that gives hope.
/**
* a sequencer orders transactions
*
* Any transactions queued under a given sequencer will be applied in
* sequence. Transactions queued under different sequencers may run
* in parallel.
*/I performed the same set of experiments as in Part 1, both with an without journaling mode enabled, with a fixed set of 64 clients and varied the number of objects in a stripe group from 1 to 64.
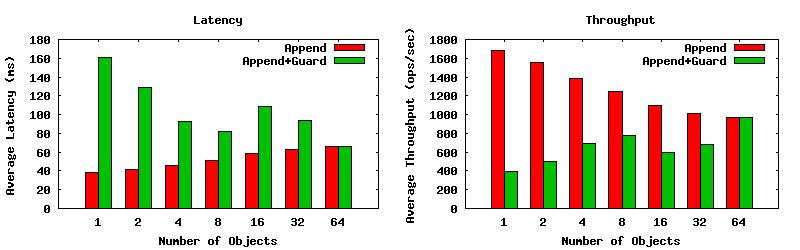
Parallel Journaling Mode
The throughput of the non-guarded append drops in performance as expected because of the random I/O induced from writing to separate objects. As for the guarded appends, performance increases quite a lot compared to the single object case, and roughly performs on par with the non-guarded append operations. Sweet.
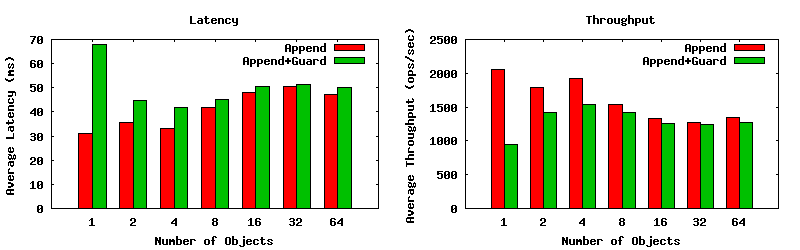
Non-parallel Journal Mode
Without the parallel journaling mode enabled, the trends are effectively the same with reduced overall throughput.