Introduction to the ZLog Transaction Key-Value Store
TweetToday I'm going to introduce a new project that we have started intended to provide a general purpose, distributed, transactional key-value store on top ZLog. Readers of this blog should be familiar with ZLog as the high-performance distributed shared-log that runs on top of Ceph and RADOS. For readers unfamiliar with the ZLog project I recommend reading this. In a nutshell the ZLog project provides a high-performance shared-log abstraction with serializability guarantees. It takes advantage of the programmability of Ceph, so you don't need new hardware or a separate cluster to use this new storage interface.
Over the past year or so we've built out a lot of infrastructure related to ZLog, but have neglected to show how it can be used to build distributed applications and services. To address this we have started development of a transactional key-value store that runs on top of ZLog. The design of the store is based on the three very interesting papers. We won't dive into the these papers in detail today, and instead I'll briefly introduce the high-level concepts and describe the internal functionality while introducing the transactional interface.
The ZLog project is generously funded by the Center for Research in Open Source Software (CROSS), an organization at the University of California, Santa Cruz that funds research projects with potential for making open-source contributions.
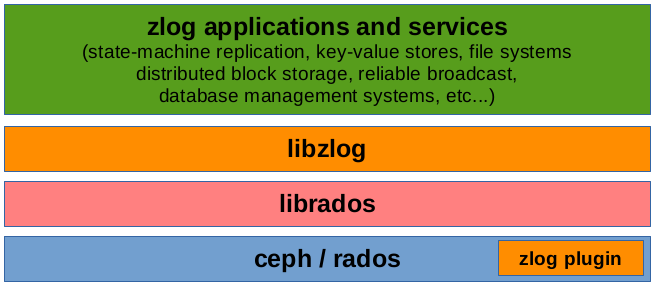
The ZLog Stack
The ZLog library sits on top of Ceph and RADOS (for storage, replication, and
distribution), and injects a plugin into Ceph to provide low-level
transactional semantics required for the ZLog / CORFU protocol. Users of ZLog
are given a simple interface that consists of append, read, and tail interfaces
(as well as others; check the related links above for more ZLog details).
Today we'll be looking at an example of an application that occupies the top
slot: a key-value store running on top of ZLog.
Next we'll describe the key-value storage and how it is mapped onto the shared-log abstraction.
The ZLog KV-Store and Immutability
The basis for the key-value store on top of ZLog is a copy-on-write red-black tree, where conceptually each mutation to the tree creates a new root that is stored in the log, and contains back pointers into sub-trees that are shared between versions. A full discussion of the design and implementation is beyond the scope of this post. We'll show at a high-level how the versions and pointers are maintained through a series of examples.
The following code snippet shows how we open the database by providing a reference to a log, and then construct a transaction that inserts a key-value pair with a key of "67".
{
// open the database
auto db = DB::Open(my_log);
// run the optimistic transaction
auto txn = db.BeginTransaction();
txn.Put("67", "val");
txn.Commit();
}
The following diagram shows the resulting log-structured tree that results from executing 6 insertion transactions. First we'll consider the insertion of the keys "67" and "18", shown below to the left labeled as "root 1" and "root 2". The first insertion following the empty tree (i.e. "root 0") results in a single root node, and inserting "18" results in a new left child of the root in next frame ("root 2").
The "root N" label in each box corresponds to the position in the underlying log of the corresponding tree generated by that transaction.
The next insertion of key "95" illustrates the log-structured nature of the data structure. While "95" becomes the new right child of the root, the left tree is shared with the previous tree ("root 2"). That is, this is a persistent, copy-on-write data structure. The label on each edge gives the physical address of the link in the form "log-position:offset" where offset is the identifier of the node within the serialization of the tree at a particular log position. These pointers may be directed at nodes within the current position, at nodes in previous transactions, but will never point forward in the log.
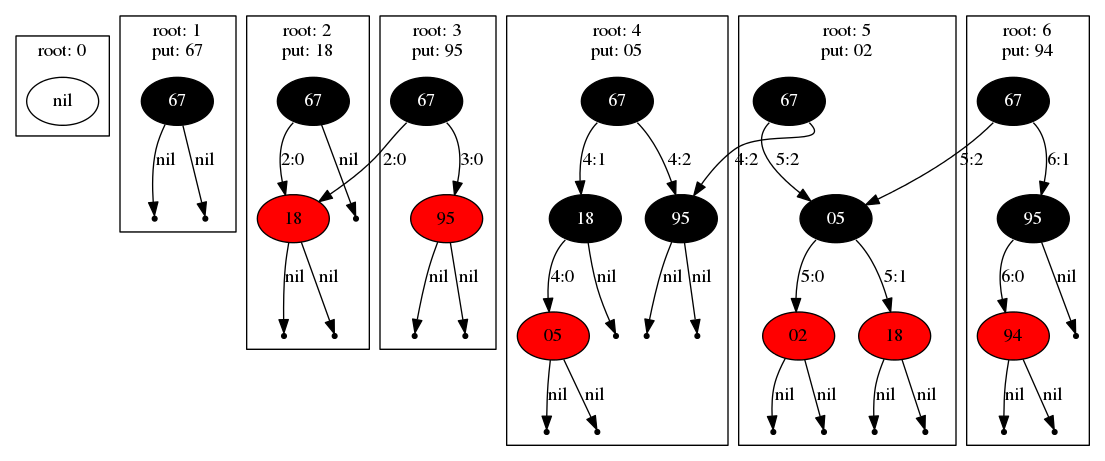
Next the insertion of key "05" causes a re-coloring resulting in no shared sub-trees (this is common when the tree is first being constructed). Finally the insertion of keys "02" and "94" both result in new trees with shared sub trees.
One of the major benefits of this design is the immutability of the structure. Notice that each log position defines a new root. What this means in practice is that long running queries can operate on a snapshot of the database without affecting on-going and arriving queries that may modify the current state of the database. It is beyond the scope of this post, but with concurrent tree operations optimistic concurrency control is used to support simultaneous queries (more on that in the future).
Multi-Operation Transactions
The design supports multiple operations (reads and writes) per transaction. For instance below the first transaction inserts keys "94" and "06", resulting in the tree shown in "root 1".
// PUT: 94, 06
auto txn = db.BeginTransaction();
txn.Put("94", "val");
txn.Put("06", "val");
txn.Commit();
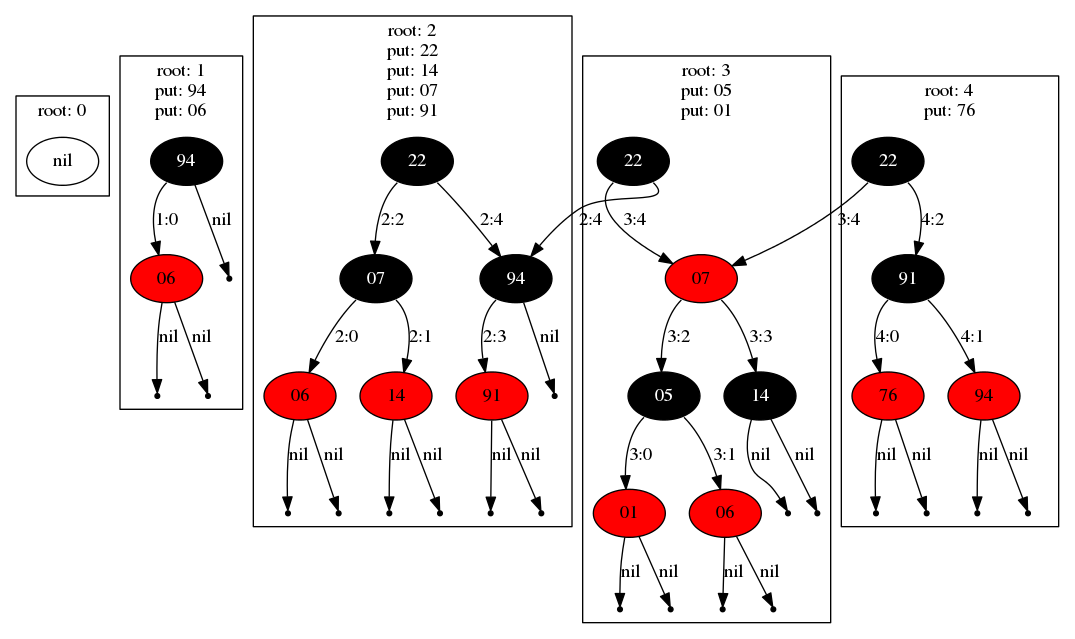
The next two transactions form the larger trees shown at "root 2" and "root 3", and the third that inserts key "76" shares a large proportion of the previous tree as its left child.
// PUT: 22, 14, 07, 91
txn = db.BeginTransaction();
txn.Put("22", "val");
txn.Put("14", "val");
txn.Put("07", "val");
txn.Put("91", "val");
txn.Commit();
// PUT: 05, 01
txn = db.BeginTransaction();
txn.Put("05", "val");
txn.Put("01", "val");
txn.Commit();
// PUT: 76
txn = db.BeginTransaction();
txn.Put("76", "val");
txn.Commit();
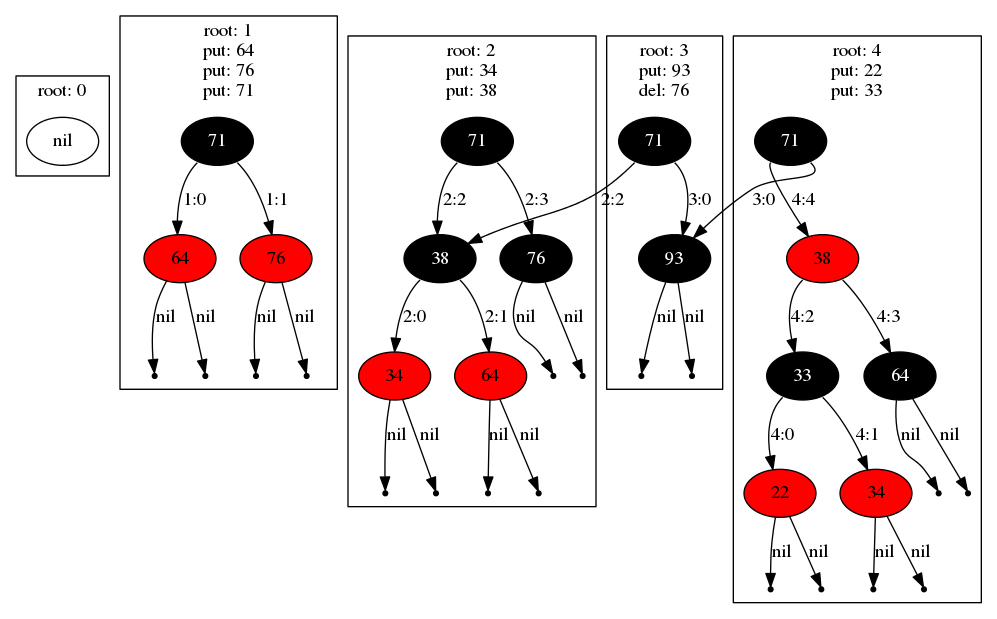
Both inserts and deletes can be combined into a single transaction. Notice in the diagram below that the transaction that creates "root 3" combines an insertion of a new key "93" and the removal of the existing key "76", while still maintaining pointers to shared sub-trees:
...
txn = db.BeginTransaction();
txn.Put("93", "val");
txn.Delete("76");
txn.Commit();
...
Iteration and Snapshots
The key-value store exposes an iterator that has an interface design based on the RocksDB iterator. The following code snippet shows how to print all key-value pairs in the database:
auto it = db.NewIterator();
while (it.Valid()) {
std::cout << it.key() << " " it.value() << std::endl;
it.Next();
}
By default the NewIterator method will access the latest version of the
database. A snapshot can be taken and later read by an iterator:
auto ss = db.GetSnapshot();
// modify db ...
// this iterator will not observe the previous modifications
auto it = db.NewIterator(ss);
while (it.Valid()) {
std::cout << it.key() << " " it.value() << std::endl;
it.Next();
}
Here is a summary of the full iterator interface. I've removed the comments as the method names should be self-explanatory:
class Iterator {
public:
Iterator(Snapshot snapshot);
// true iff iterator points to a valid entry
bool Valid() const;
// reposition the iterator
void SeekToFirst();
void SeekToLast();
void Seek(const std::string& target);
// navigation
void Next();
void Prev();
// retrieve the current key-value entry
std::string key() const;
std::string value() const;
int status() const;
...
};
What's Next
While we currently have a fully functioning implementation, there remains a lot of work. Things that are on the short-list include:
Cache clearing. Currently when a node pointer is resolved by reading it from the log it is cached. This eliminates duplicate entries in memory, and makes accessing frequently used entries quick. However we do not currently trim the cache. What we need is to implement trimming which is tricky because we want to effectively prune a sub-tree while not affecting on-going queries.
Meld implementation. The design supports multiple nodes interacting with the database in parallel, but to make this efficient requires a carefully designed MVCC algorithm. Currently we provide safety for multiple clients, but efficiency is poor due to frequent aborts with multiple clients. Prior work provides a solution and we'll be integrating the approach into our design (see related links at the beginning of the post for more information on these algorithms).
Apps. We'll be working to hook up existing applications to demonstrate the system, as well as cleaning up the API for developers to build their own apps. The API is very similar to the transaction API for RocksDB so existing applications (e.g. YCSB, MyRocks) should be readily available.
Misc. There is a lot of miscellaneous work to be done such as switching to a more generic key/value type (e.g. RocksDB/LevelDB Slice or Ceph bufferlist), optimizing our use of
shared_ptrs which will be relevant for the caching work, and adding a means for sharing key-value pairs among duplicate nodes.
Check back often for updates :)